
什么是Ra计划
一张角色美术工作流的体验卡,主打一个学学再说。大概会捋一下AI原画-雕刻-模型-材质-绑定-动画的全流程,是个大坑。

Part1 原画
这一趴其实是来凑数的!Ra的原画是直接Midjourney抽出来的,其精度也达不到[原画]的要求,后期一边建模一边创作。
本文是张冠李戴的另一个MJ画风模型训练,但是基本是一样的原理,我是不介意多水一篇啦。
StableDiffusionv1.5
在实习期间接触了很多AI相关的尝试,关于AI原画的知识也来源于工作的积累。
11月了才来发这篇文章属实是大迟特迟,但还是想把之前学习的一些东西记录一下。所以先行预警,这是一篇(至少)过时了4个月且七拼八凑的训练笔记,不是教程!
不是教程!
请希望学习模型训练的读者查找最新SDXL的相关教程。
训练原理
模型微调与DreamBooth
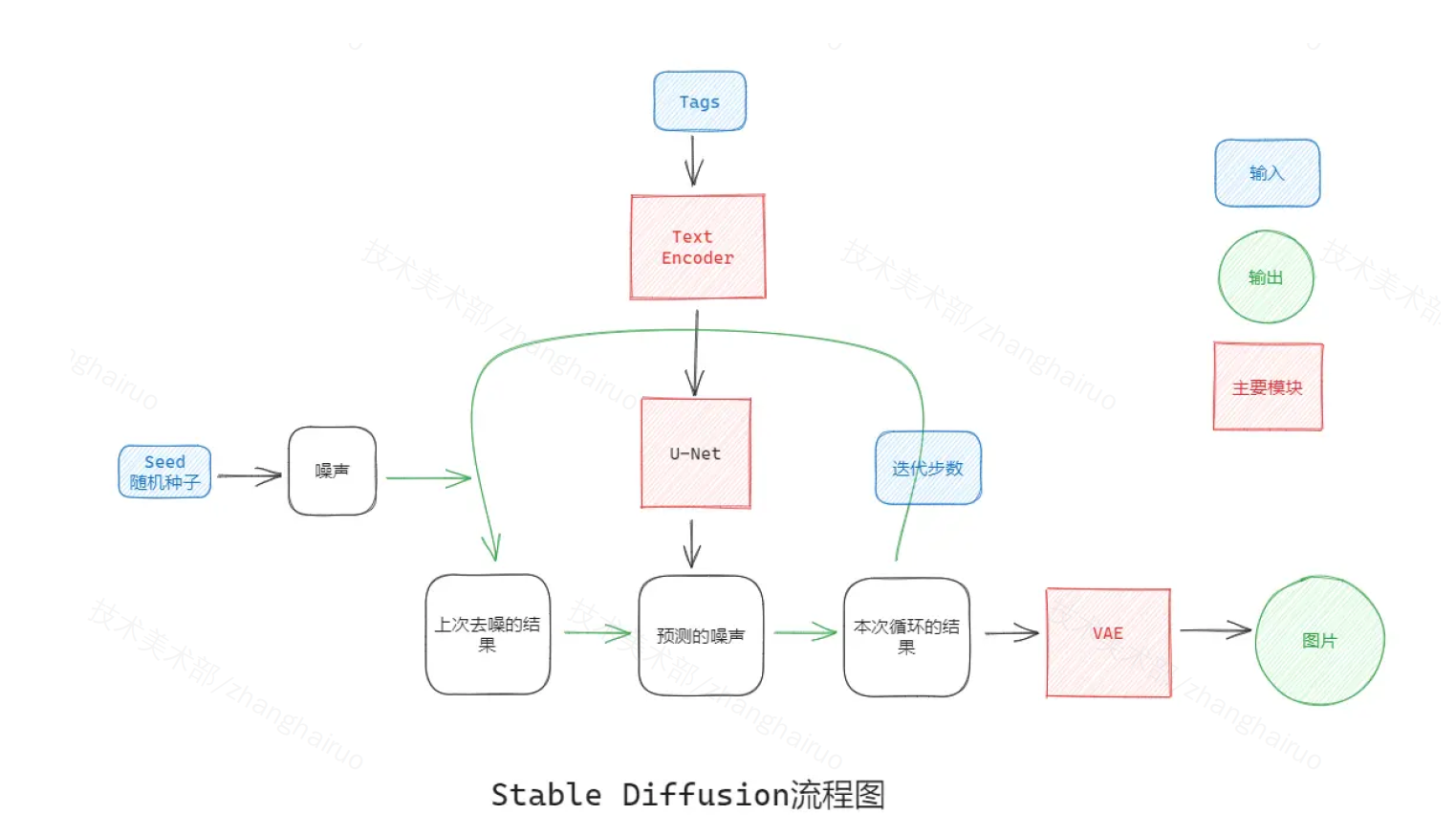
模型微调
Stable Diffusion 的图像生成主要涉及三个主要模块:CLIP(Text Encoder),U-Net 和 VAE。
-
CLIP:将 Prompt 转化成模型能够理解的向量
-
U-Net:图像生成的主要网络,由于结构与字母 U 相似而得名
- VAE:将噪声转化成输出图像
模型微调的过程就是用少量的图像对 Text Encoder 和 U-Net 两部分做微调,使模型学会我们新加入的风格或概念。但是由于微调过程中素材量较低,可能会发生过度拟合(比如训练集中只有趴着的小狗,就无法生成站着 or 跑步的小狗)和语言偏移(随微调逐渐失去语言的句法和语义知识)。
DreamBooth
为了避免这两个问题,DreamBooth 的训练方法提出了 Prior-Preservation Loss 先验损失,通过自己先生成一些图像(也是我教程里的 class image),来保留先验损失权重。用模型自己生成的样本来监督模型,以便在 few-shot(小样本,可以理解为几张图) 微调开始后保留先验知识。
举例中,我们训练特定长相的小狗,只有四张图片作为训练集。我们称它为 sks dog,其中 sks 是一个特殊的 token 关键词,dog 为狗狗的大类 class。dreambooth 会根据 dog 这个 class 生成大量其他小狗的图像,在学习新概念 sks 的特征时保留对狗狗大类的认知。

在现在使用的各种脚本中,先验损失保留这个过程也被称为“正则化”。另外允许训练时使用自己准备的训练集,即“reg dataset”。如果需要使用正则化,正则训练集的图像就准备同类别图像即可(例如训练角色 - 同性别的单人图)。
LoRA
通过 Dreambooth 和传统的微调方法,我们会得到“大模型”一般在 4-7GB 左右,且训练的过程占用显存较高,用时也比较久。LoRA 是在 Dreambooth/ 基础微调方法的基础上产生的。
LoRA ,英文全称Low-Rank Adaptation of Large Language Models ,直译为大语言模型的低阶适应,这是微软的研究人员为了解决大语言模型微调而开发的一项技术。LoRA建议冻结预训练模型的权重并在每个Transformer块中注入可训练层(秩-分解矩阵)。因为不需要为大多数模型权重计算梯度,所以大大减少了需要训练参数的数量并且降低了GPU的内存要求。
简单来说, LoRA只训练模型中的一部分参数。训练比例由秩dim(rank)决定,dim越大,显存要求越高,生成的模型文件也越大,也可以学到更多图像特征。一般dim128的LoRA训练会生成144MB左右的LoRA模型,生成时需要搭配大模型使用。
dim 并非越大越好,通常 128 已经能够满足绝大多数训练需求。人物训练甚至只需要 32-64 即可。
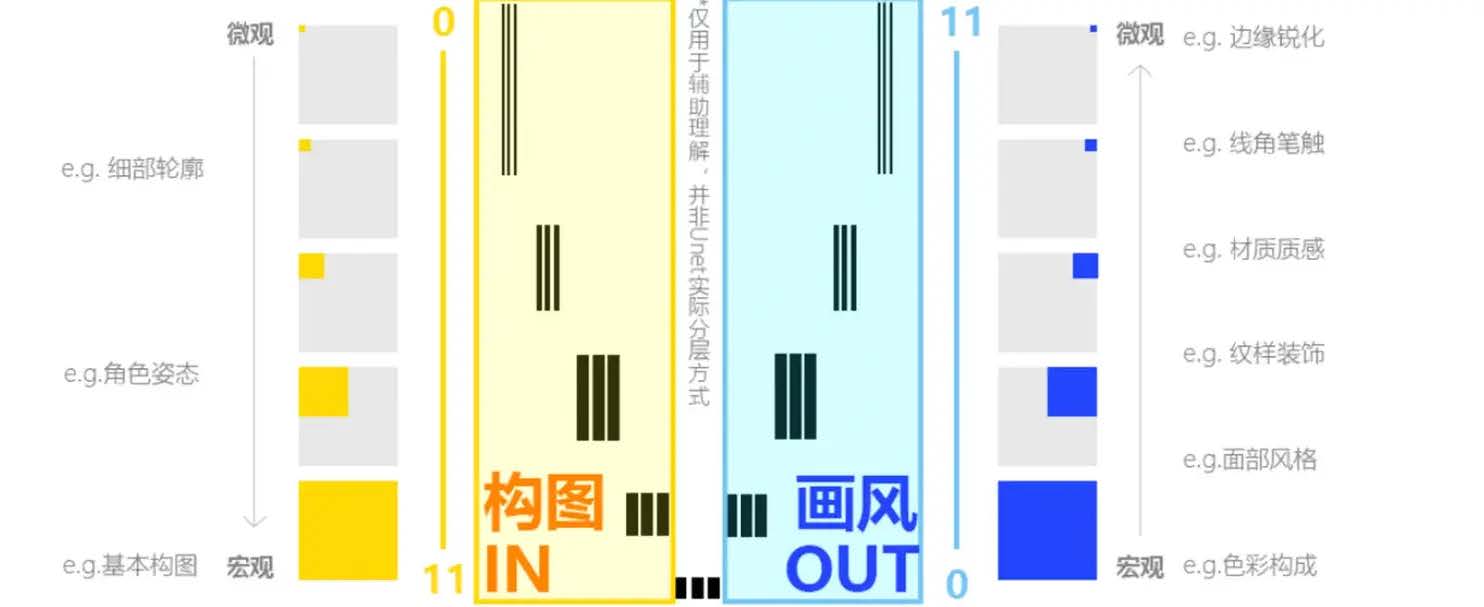
U-Net与层
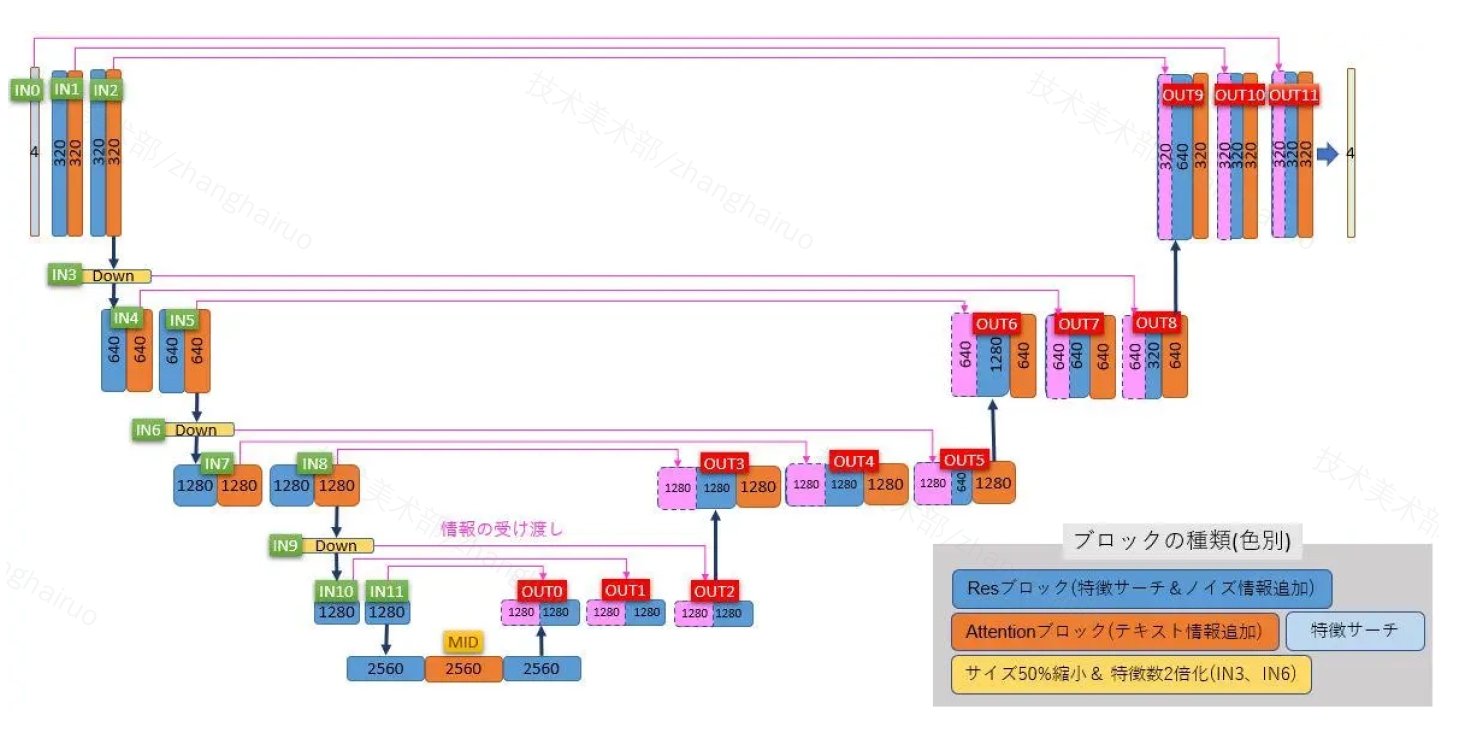
UNet 是图像生成的主要结构,整体形态呈 U 形。上图是 Stablediffusion 中使用的 Unet 结构。图像从左上角输入,由左向右传递,最终从右上角输出。
左侧下行会经历三次降采样,共包含 IN0-IN11 共 12 层。中间是 MID 层。右侧上行会经历三次升采样(IN3、IN6、IN9),共包含 OUT0-OUT12 共 12 层。横向粉色的连线表明特征信息的传递,IN 与 OUT 的部分层会相互关联影响。
LoRA 通过 Attention 模块干涉所有图中橙色的层。而 Lycoris 的一些结构可以干涉所有 Res 层,即深蓝色的层。
层的差别 - 上&下
在实际效果上,偏上的层决定画面上更细微的特征,例如材质、边缘等。偏下的层决定宏观的特征,例如构图、色彩等。这主要是受到降采样的影响:
在 IN0 中,图像首先被缩放到原图的 1/8,然后再 IN3/6/9 时再分别缩小 1/2。 Stablediffusion 使用 3x3 的滤波核提取特征,当图片缩小后,滤波核能够覆盖的比例就会更大,即提取更宏观的特征。
(这也是为什么我们的图像像素最好是 8 的倍数)
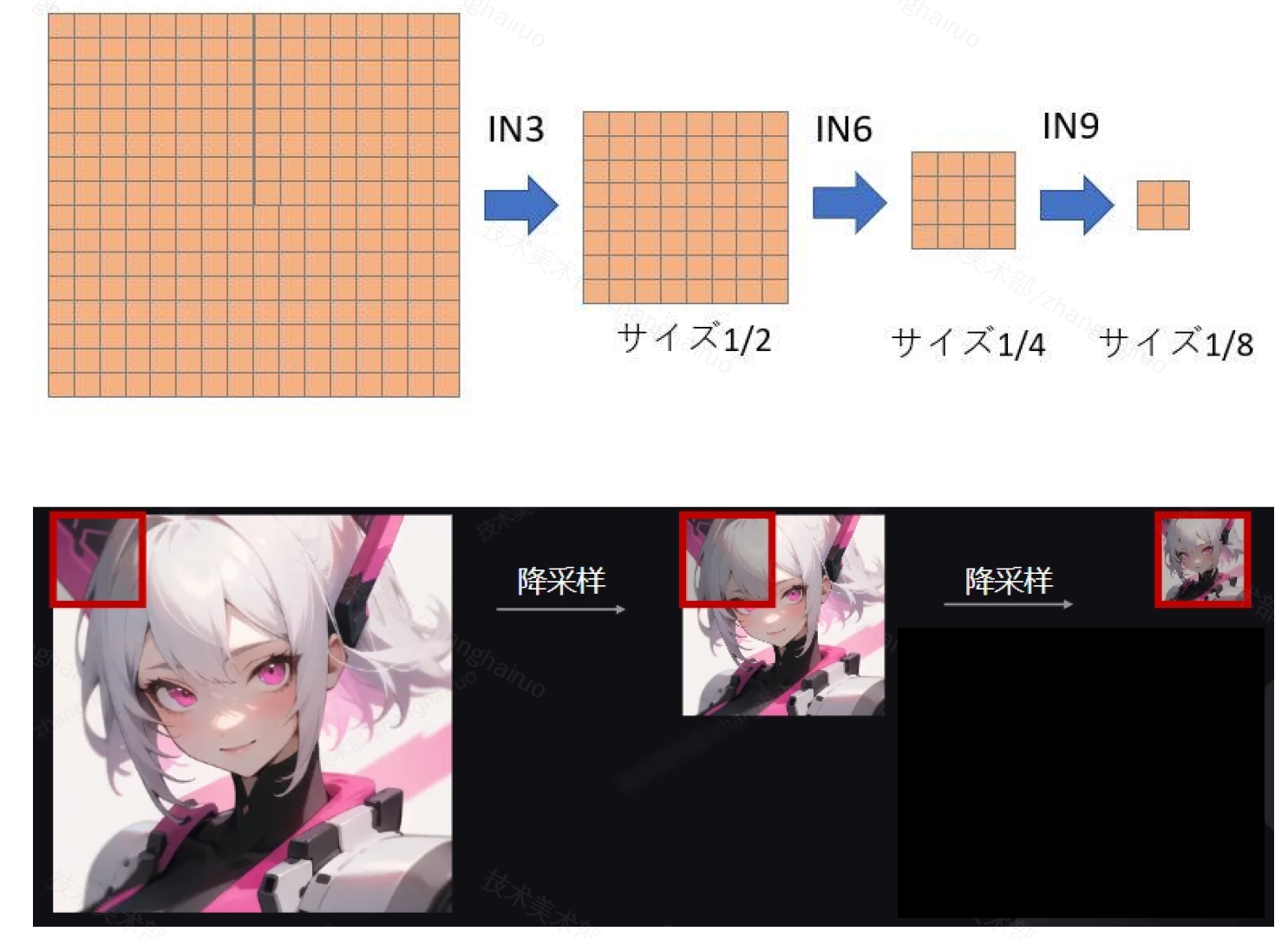
在相似构图下,各画面元素在图像中占比是相似的,这意味着对应提取特征的层是能够推理得到的。而图像生成的场合中,我们使用最多的是 cowboy shot,即人物腰部及以上的特写。在这样的构图内,我们可以用下面这张表格来推理各层对各个画面元素的影响程度。
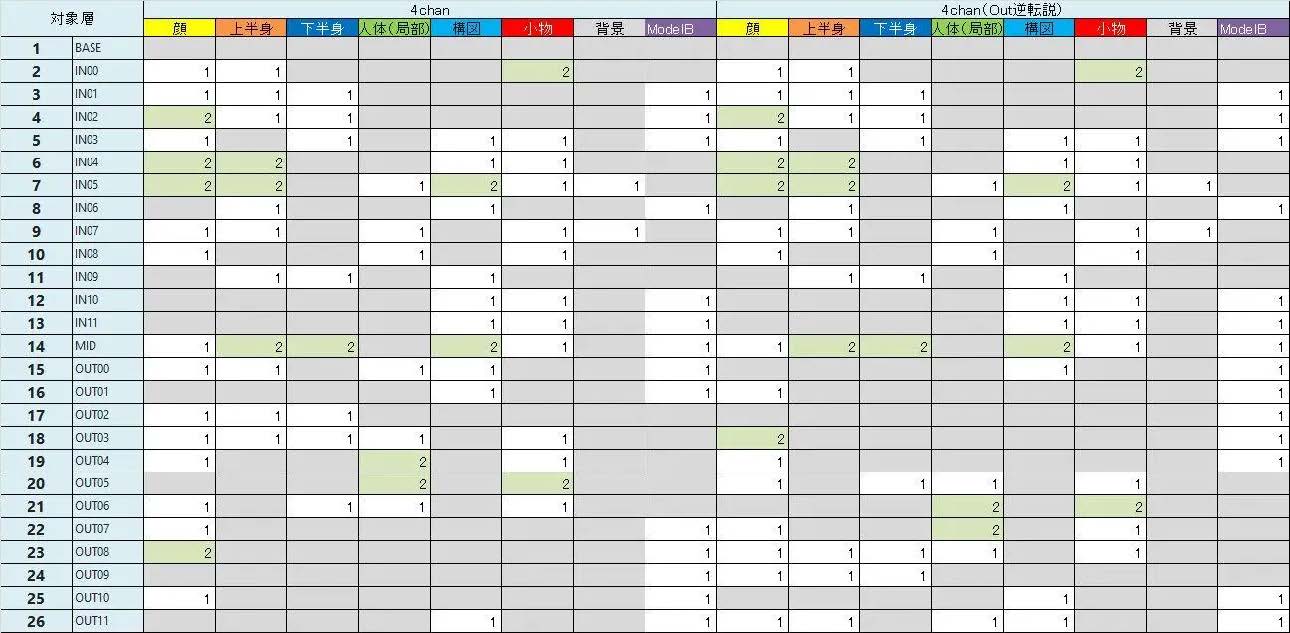
层的差别 - 左&右
可以抽象理解为 IN 的模块主要控制构图,OUT 的模块主要控制风格。
训练步骤
耍赖:
由于迟了4个月,当前的插件版本肯定已经有大幅度的更新。因此关于插件/脚本使用的部分直接跳过。
训练目的
训练特定画风的模型。
在这里我们希望画的是Midjourney很擅长的Q版2.5d小人。希望在SD中还原渲染质感,且利用SD更高的可控性完成绘制。
这次实验使用的是Dreambooth,但如果有人读到这里且真的想尝试画风模型的训练,首选还是LoRA。
素材准备
收集素材集
-
人物:
a. 真人:
【数量】 10-100
【要求】 面部信息清晰,不同角度 / 衣着 / 背景

【正则素材集数量】大量(>= 素材数量,一般 100 张以上)
【正则素材集内容】写实男人 / 女人(对应性别)图像,可使用底模生成。
b.二次元:
【数量】 8-30
【要求】 大头不同角度,全身不同角度
2.画风:
【数量】~100
【内容】推荐画面内容占比 :70% 人 20% 场景 10% 动物 / 物体。实际根据具体需求而定,只有一种内容(道具 / 场景 /...)也可以训练。
处理素材集
- 避免水印 /UI
- 避免小于 512 分辨率图像
- 避免长图
- 避免同名文件(注意 jpg 和 png 也不能同名)
- 主体明确,避免一张图上有多个人
素材集打标
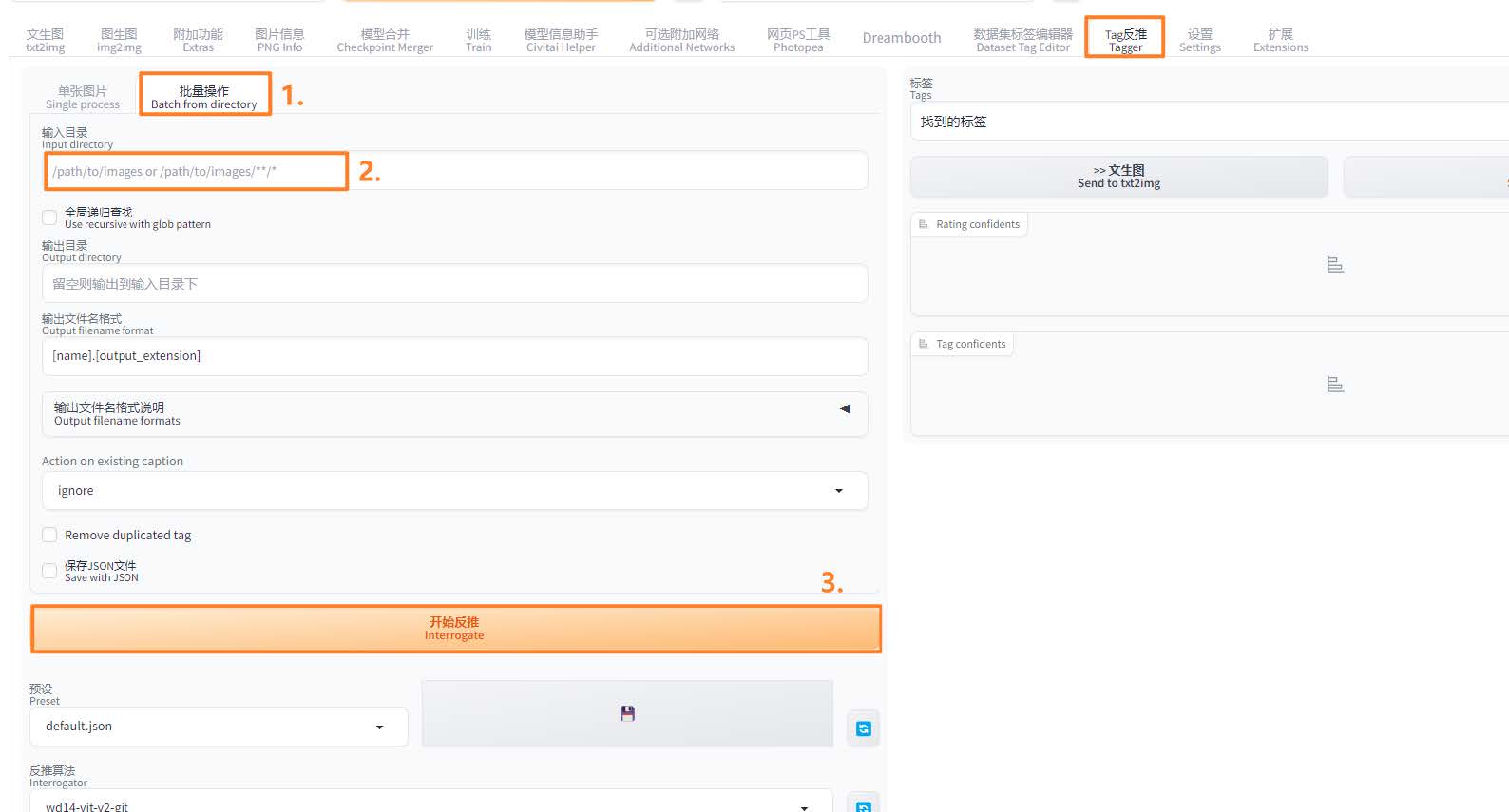
该插件用于批量生成图片同名的 txt 文件,描述图像的内容。
使用 WebUI tagger 插件:
在 Extension 中通过 URL 安装 Tagger 插件:
https://github.com/picobyte/stable-diffusion-webui-wd14-tagger.git安装好后重启 WebUI。
标签处理
画风模型可跳过这一步。
使用 WebUI Dataset Tag Editor 插件
处理原则:训练角色 Lora 时,我们希望模型从数据集中学习角色的主要特征,建立特征与角色的对应关系。因此,数据集中的 tag 里不应该包含描述角色特征的 tag,例如发色、衣着等等;而描述姿势、表情的 tag 则需要保留。另外还要在 tag 的句首(权重最高)添加角色名。

素材集更名
-
在 lora-scripts 脚本目录下新建 train 文件夹,用于存放之后所有训练素材。
-
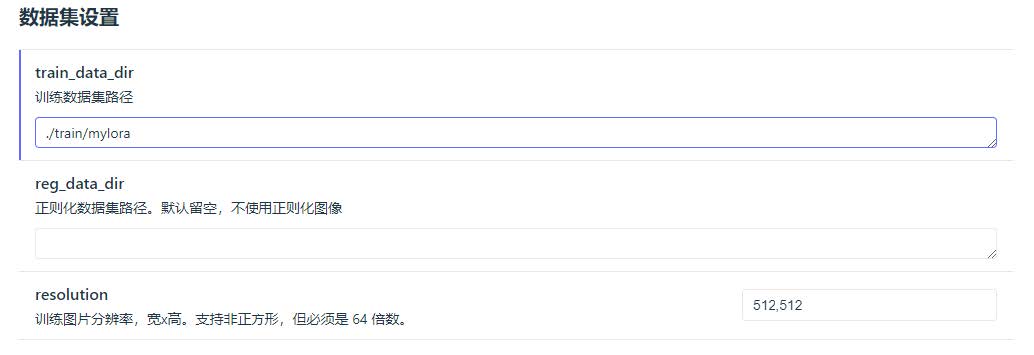
在 train 内新建一个本次训练的文件夹,例如 myLoRA 。
- 在 myLoRA 内新建子文件夹,用于存放之前处理的素材集图片 & 同名 txt。一次训练可以同时训练多个概念,每个概念的图片应该位于不同子文件夹内。子文件夹的命名格式为 重复次数_概念关键词 。
【人物】一般 20 张素材左右时 设置为 7 【画风】一般 50 张素材左右时 设置为 5
训练参数
-
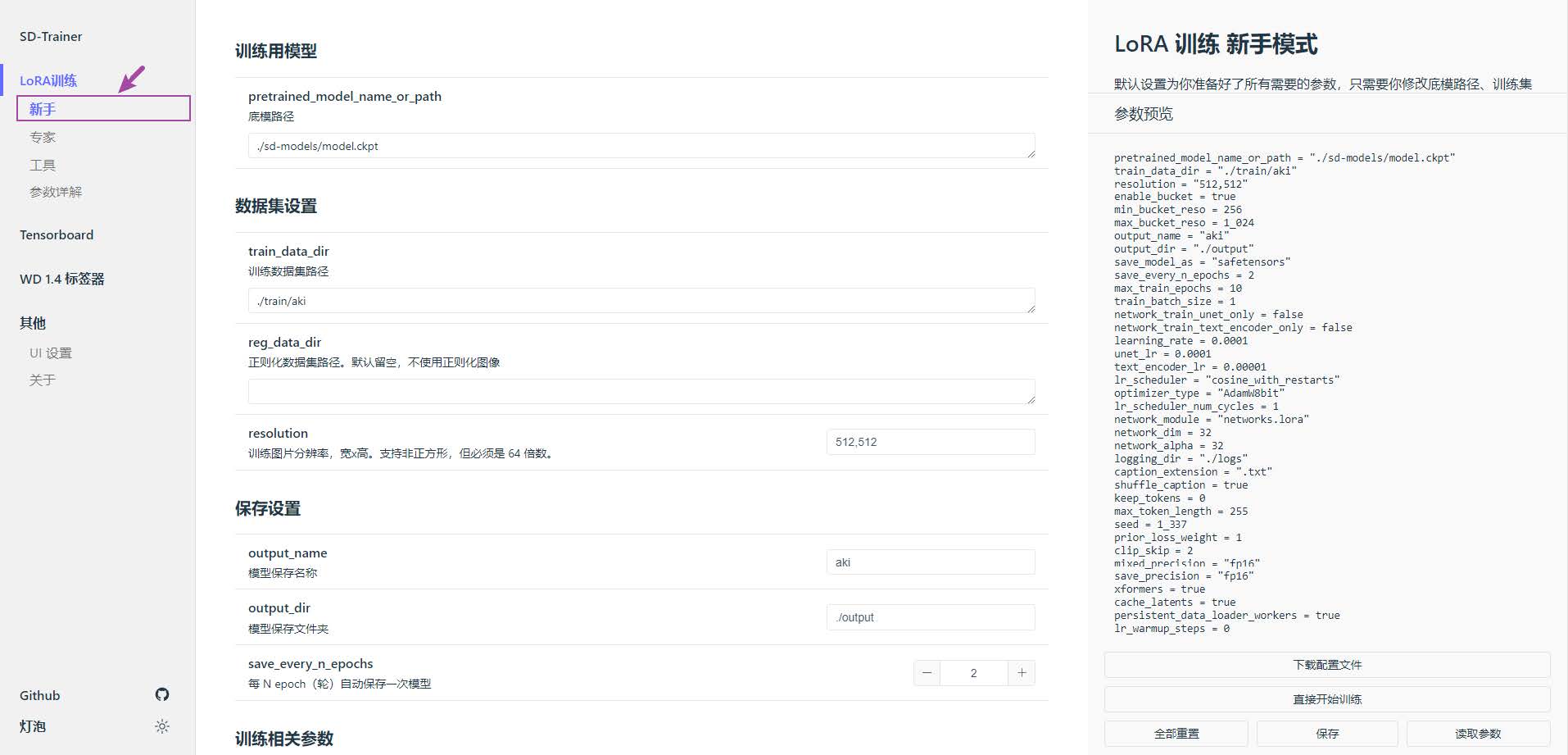
打开 lora-scripts 文件夹,右键 run_gui.ps1 - 使用 powershell 运行(linux 为 run_gui.sh ),即自动在浏览器上打开 GUI,点击 LoRA 训练 - 新手,进入训练配置页面;
-
将底模复制到 lora-scripts/sd-models,修改底模文件名
a.写实模型使用官方 v1.5 模型
b. 二次元模型使用 NovelAI 模型

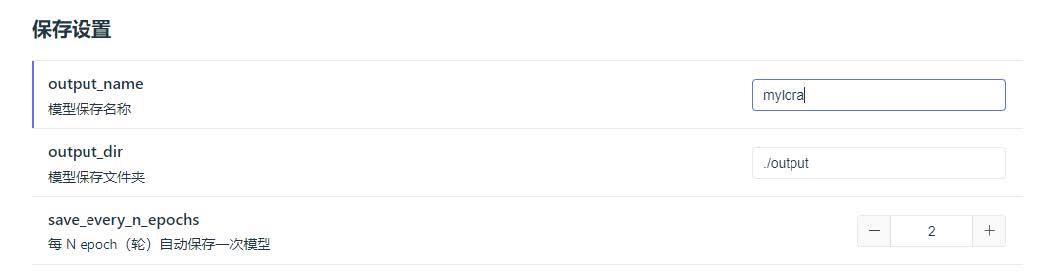
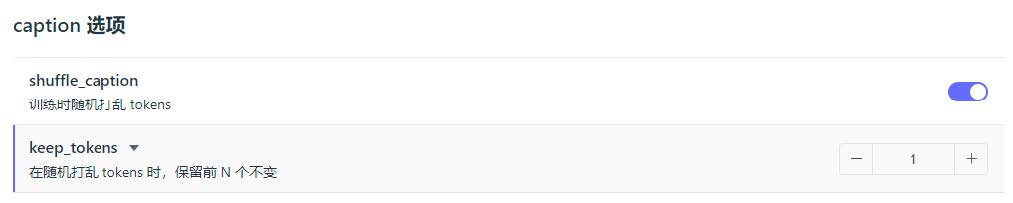

训练参数
训练步数 Steps - epoch - batchsize
训练步数 = epoch (重复次数 图片数 ) * 正则系数 / batch size / 梯度累加步数
理想的训练步数?
训练步数与学习率息息相关,在 UNet 学习率 1e-4 时,一般来说图片较少的时候训练人物需要至少 1000 步,训练画风则需要至少 2500 步,训练概念则需要至少 3000 步。
学习率更大时,可以适当减少步数,但二者并不符合线性关系,使用两倍的学习率需要使用比之前步数的一半更多的步数。
Epoch
重复轮次。每轮次训练完成后可进行模型保存、示例图采样等。
重复次数(Kohya 系限定)
重复次数即训练集文件夹名的第一部分,决定此文件夹内图片的重复次数。
- 对于【不使用正则】【单概念】的训练,不需要特别关注重复次数。它与 epoch共同调节总步数,维持二者乘积为理想总步数即可。
- 【多概念】的情况:每个概念的训练集数量可能不相等, 通过各概念的重复系数可调整每组素材的训练程度。一般会使各概念的重复次数 * 图片数基本相等。
- 【正则化】的情况:一般正则图像集数量会远大于训练素材数,通过重复训练素材使概念的重复次数 * 概念图像数 ≥ 正则图象数,且二者尽可能接近
正则系数 Regulatization factor
使用正则时为 2,不使用时为 1.
Batch size & 梯度累加
Batch size 越大梯度越稳定,也可以使用更大的学习率来加速收敛,但是占用显存也更大: 6-8GB - 保持 1;
10GB - set to 2
12GB - set to 3
注意 batch size 调大时,学习率也需要更高。
梯度累加 gradient_accumulation_steps
梯度累积步数,用于在小显存上模拟大 batch size 的效果。
如果显存足够使用 4 以上的 batch size 就没必要启用。
学习率 lr - loss - 过拟合 & 欠拟合
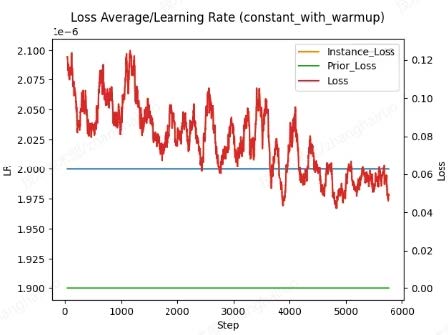
学习率可以理解为每一步学习的比例,总体学习的程度可以量化为loss,描述扩散生成图像与训练图像的差别。在正常的训练过程中,loss应呈整体下降趋势,局部的起伏变化是正常的。
理想的 loss 值一般为 0.05 左右,当 loss 大于 0.15,训练特征表现不充分,一般称为欠拟合;当 loss 接近于 0 时,模型出图可能会产生扭曲 / 只能生成训练集中的图像,称为过拟合。

学习率过大:如果大趋势上 loss 值不降反增,生成图像接近潜在噪声(俗称炸炉),一般诱因是学习率过大导致收敛失败。就需要调小学习率。
学习率过小:可能需要加倍的步数才能接近收敛,训练速度慢。
学习率的规划策略 lr_scheduler:
- constant,常量不变
- constant_with_warmup 线性增加后保持常量不变
- linear 线性增加线性减少
- polynomial 线性增加后平滑衰减
- cosine 余弦波曲线
- cosine_with_restarts 余弦波硬重启,瞬间最大值(lr_scheduler_num_cycles 配置余弦退火重启次数,不应该超过 4 次)
一般使用 consine_with_restarts 或 cosine,整体学习率会呈余弦曲线下降:即早期 loss 高时,学习率高;后期 loss 低时学习率也降低,防止过拟合。
如果开启预热,预热步数应该占总步数的 5%-10%。
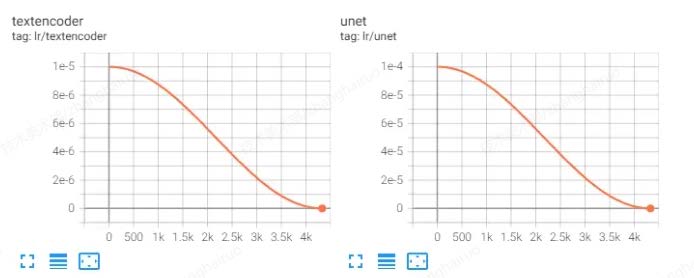
分别调节 Unet 于 Text-encoder 的学习率
UNet 和 TE 的学习率通常是不同的,因为学习难度不同,通常 UNet 的学习率会比 TE 高 。如果 UNet 训练不足,那么生成的图会不像,UNet 训练过度会导致面部扭曲或者产生大量色块。TE 训练不足会让出图对 Prompt 的服从度低,TE 训练过度则会生成多余的物品。
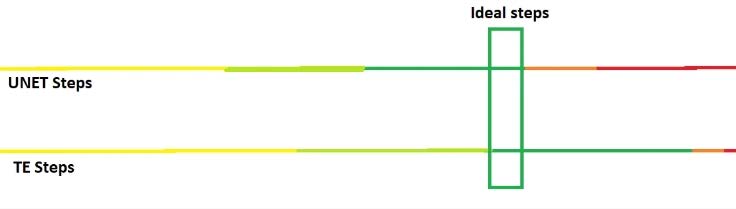
查看当前的学习率&loss
Kohya系:建议使用tensorboard或wandb
Dreambooth脚本:训练时GUI右侧提供及时更新的图表
优化器
常用优化器:
- AdamW8bit:启用的 int8 优化的 AdamW 优化器,默认选项。
- Lion:loss 最终下降更低,同时占用显存更小,可能需要更大的 batch size 以保持梯度更新稳定,更慢。
- D-Adaptation:FB 发表的自适应学习率的优化器,调参简单,无需手动控制学习率,但是占用显存巨大(通常需要大于 8G)。使用时设置学习率为 1 即可,同时学习率调整策略使用constant。
- Prodigy:可自适应 Dylora,全程自适应训练,使用时设置学习率为 1 即可。
不同的网络结构
不同网络结构对应不同的矩阵低秩分解方法。LoRA 是老祖宗,只控制模型中的线性层和 1x1 卷积层,后续的不同网络结构都是在 LoRA 的基础上进行改进。
LyCORIS 对其进行改进,添加了其他几种算法:
LoCon 加入了对卷积层 (Conv) 的控制
LoHa(哈达玛积)和 LoKr(克罗内克积)
IA3
理论上来说 LyCORIS 会比 LoRA 拥有更加强的微调效果,但是也更加容易过拟合。
需要注意的是,不同的网络结构一般需要对应不同的 dim 以及学习率。
网络大小dim(rank)
网络大小应该根据实际的训练集图片数量和使用的网络结构决定
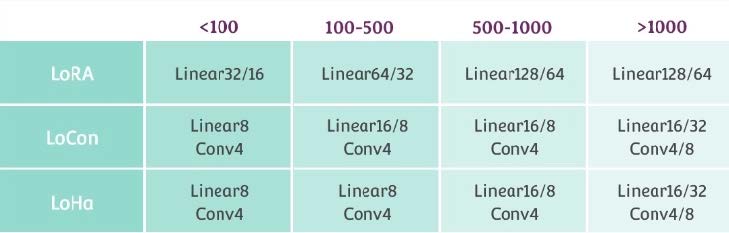
上表中值为秋叶的角色训练推荐值,训练画风和概念需要适当增加 Linear 部分大小。推荐值并非对各个不同的数据集都是最优的,需要自己实验得出最优。Conv 的大小最好不要超过 8。
DyLoRA
DyLoRA 是在这篇论文中提出的 DyLoRA: Parameter Efficient Tuning of Pre-trained Models using Dynamic Search-Free Low-Rank Adaptation,根据论文,LoRA 的 rank 并不是越高越好,而是需要根据模型、数据集、任务等因素来寻找合适的 rank。
使用 DyLoRA 时,需要添加参数 unit , unit 应当可以被 network_dim 整除。
当 network_dim =16, unit =4 时,将可以提取 4 种 dim 的 LoRA:4/8/12/16.
网络 Alpha(network_alpha)
alpha 在训练期间缩放网络的权重,alpha 越小学习越慢,关系可以认为是负线性相关的。
一般设置为 dim/2 或者 dim/4。如果选择 1,则需要提高学习率或者使用 D-Adapation 优化器。
不同噪声
相较于 Midjourney,Stable Diffusion 很难生成具有强烈黑白对比的图像,在表现纯黑白纹理、强烈光影变化时表现劣势。通过噪声偏移 / 金字塔噪声等方式可以改善这个问题:

noise_offset 噪声偏移
通过在图片中随机添加统一的值来快速改变图片的均值(零频率)从而使模型学习能够更快学习到图片的均值从而能够生成更亮或者更暗的图片。推荐概念 0.06,画风 0.1。
multires_noise 金字塔噪声
金字塔噪声通过反复叠加不同分辨率的噪声来增加低频的部分从而达到同样的效果。
multires_noise_iterations #多分辨率噪声扩散次数,推荐 6-10,0 禁用。
multires_noise_discount #多分辨率噪声缩放倍数,推荐 0.1-0.3, 上面关掉的话禁用。
模型调试
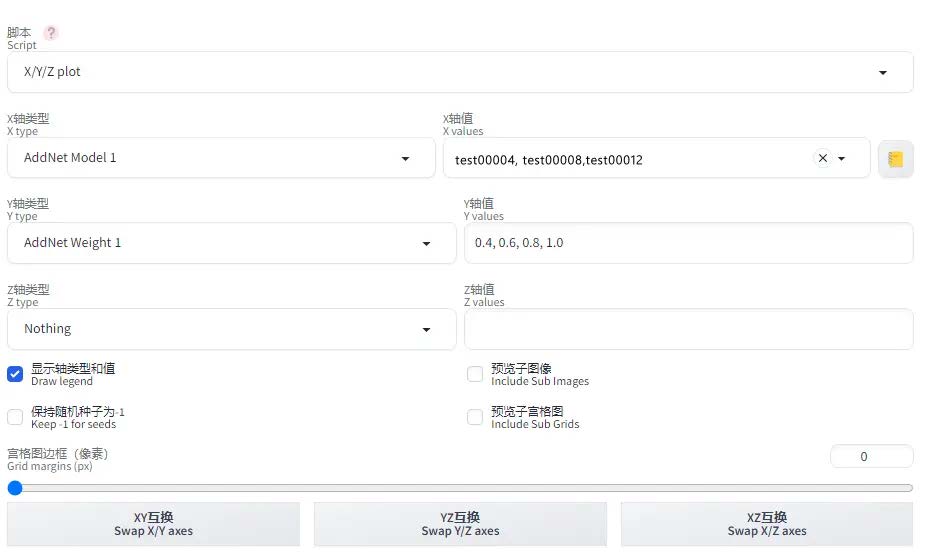
利用 XYZ Plot 脚本 +Additional Networks 生成网格图
XYZ Plot 是 Webui 自带的脚本工具,可以替换单一参数生成网格图,以对比不同步数 / 参数的训练模型,挑选最优训练成果。
Additional Networks https://github.com/kohya-ss/sd-webui-additional-networks.git
Kohya 提供的插件,可以提升附加网络的使用体验,并提供 lora mask 功能。建议安装后在设置 -Additional Networks 添加默认 lora 模型路径:
生成对比图
模型融合
使用场合
本节主要介绍大模型的分层融合。lora 的分层融合需要使用 kohya 脚本。
通过分层,可以特异的迁移大模型的某一级特征,例如修复训练过拟合的面部、人体结构;迁移画风、材质等等。

融合原理
Checkpoint Merger
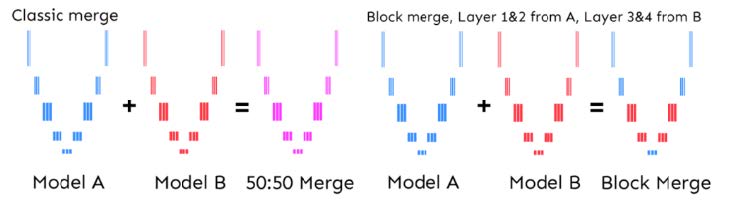
WebUI 默认插件之一,可以在[Checkpoint Merger]标签页找到。该插件可以通过特定的比例(A (1 - M) + B M)混合两个大模型的权重,从而获取介乎二者之间的效果。

结合 Unet 的分层原理(详见 训练原理),使用 Merge Block Weighted 可以分层控制融合权重,提升融合过程的可控性。
使用方法
- 使用 extension-install from URL 安装:
https://github.com/bbc-mc/sdweb-merge-block-weighted-gui
- 界面下方的 25 个滑条对应 25 个层的权重。为 0 时权重完全来自模型 A,为 1 时权重完全来自模型 B
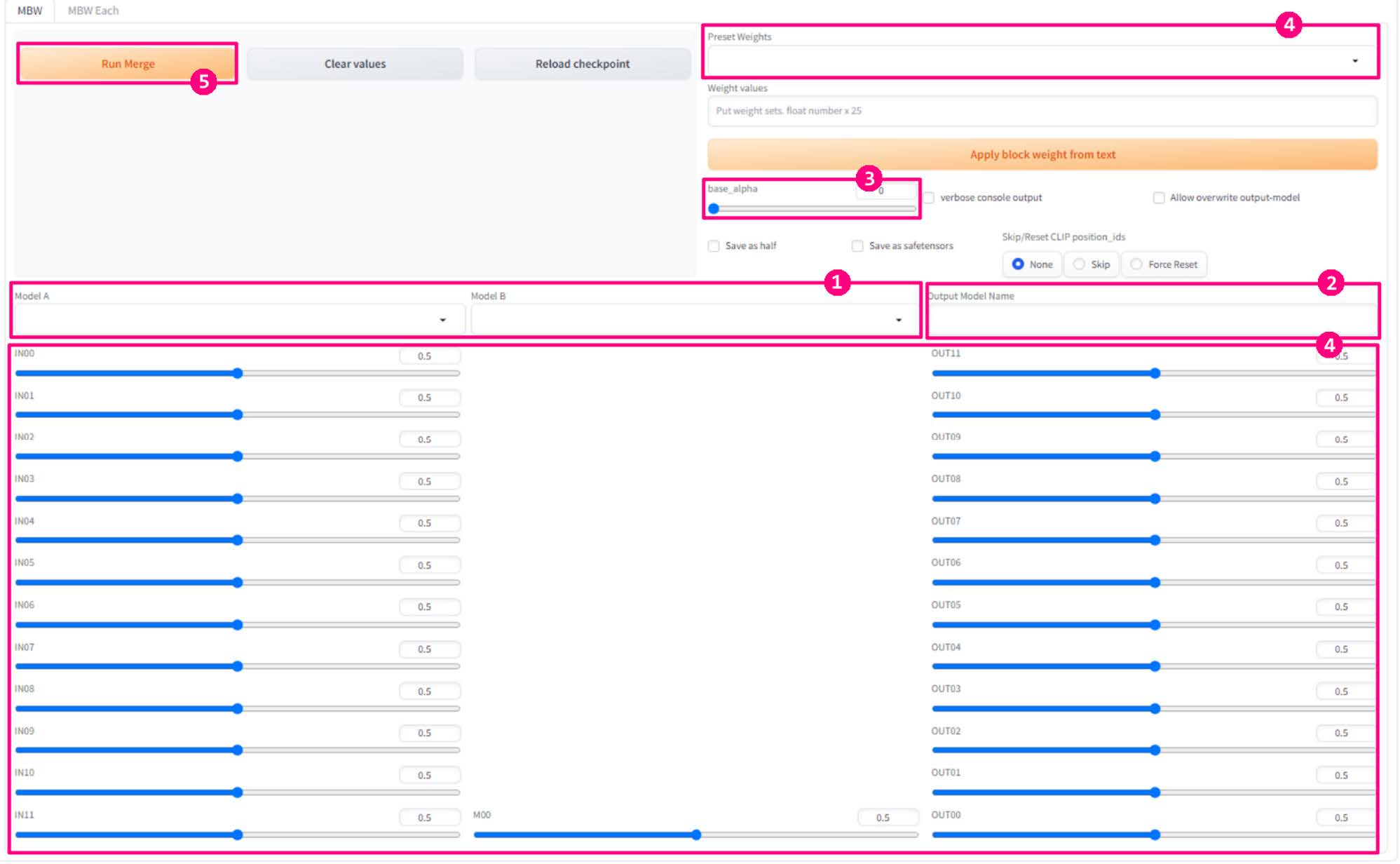
- 设置融合参数 a.设置模型 A 与模型 B3. b.设置输出模型名 c.设置 base alpha(见下) d.设置各层权重 e.点击 Run Merge f.实验模型效果,重复 1-5,进入调参地狱
base_alpha
该数值决定使用哪个模型的 text encoder。Text Encoder 中包含了训练上的[概念]。参考下方例图“Pepe the frog on beach”,其中模型 B 上训练了佩佩蛙的概念。
无论 Unet 来自哪个模型,当使用模型 B 的 Textencoder 时,就能画出蛙蛙的元素。

建议使用包含了训练概念的模型的 text encoder。数值建议保持 0(完全使用 A 模型)或 1(完全使用 B 模型),防止出现中间状态的融合。

by ERIN.Z